
基于深度学习算法的乐谱生成器:Music Eye
作者:周恩贤 计算机系
指导老师:胡晓林 计算机系
关键词:深度学习、CNN、attention、乐谱生成、音乐
摘要
我们通过改进一个现有模型,提出了一个基于全卷积神经网络的听谱模型Music Eye,能够高效快速地实现音频文件向midi事件的转换,并且能在有和弦、多音色、多声部的复杂的条件下实现高准确率的识别。
数据集制作
我们使用midi文件生成带标注的数据。通过timidity实现midi文件到音频文件的转换,并使用常数Q变换得到的频谱图。为了让模型获得相位信息,我们将频谱图分为模、实部、虚部三个通道。我们通过解析midi文件获得对应的按键事件。
为了防止过拟合,我们使用以下几个数据增强方法:1.加入麦克风录制的噪音。2.对乐曲随机移调,变速,并在乐曲头尾插入可变长度的空白。3.为各声部随机替换乐器。
考虑到运算资源的开销,我们限定每个样本的时间长度为8s。下面是数据的一个样例:

图1.输入数据样例
从左到右依次为频谱图的实部,频谱图的虚部,对应的midi事件。
模型介绍
我们所知的一个相关模型为[1],我们对该模型进行了改进。
将识谱问题表示为一个像素级二分类问题,对于常数Q变换产生的频谱图,我们让频率的坐标为对数坐标,并让一个钢琴按键对应频率轴上的4个像素。如图。模型所做的是为每一个时刻每一个按键输出按键是否被按下,按下是1,没按下是0。

图2.模型介绍示意图
其中,蓝色框从左到右依次为C的根音、一阶泛音、二阶泛音、三阶泛音,而我们最终只需要根音。由于音频是可以重叠的,根音和泛音可能会叠加在一起,会导致根音难以分离,所以这是实现的难点之一。
为了解决泛音的问题,我们在第xx和xx层使用很宽(相当于4个八度)的卷积核。为了保留较高的时间分辨率,我们只对频率轴进行池化(池化是由卷积实现的)。模型如图所示:
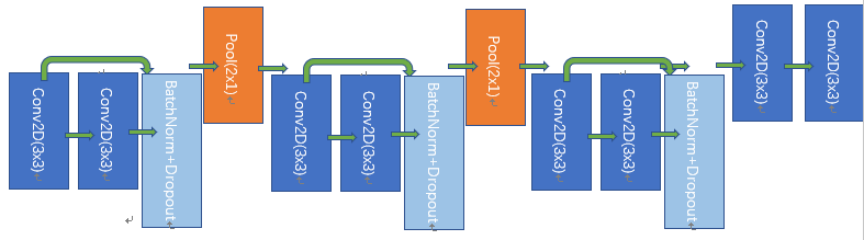
图3. Music Eye 神经网络模型
真实样本测试
由于计算资源有限,虽然我们准备了上万首midi文件,但是我们只用了其中的37首,每首通过数据增强得到4个样本,共计148个样本。但是模型依然表现出良好的性能,处理速度约为每0.5s能处理8s的录音。我们在下列几个数据上进行了测试,难度由低到高。为了能有更加直观的感受,我们在附件中提供了输入音频与从输出中重构的音频。
1. 测试集中的midi文件:千本樱,时代前进
2.YouTube上钢琴弹奏的录音: Chopin
3.扬声器播放并用麦克风录制的录音: 卡农
我们发现模型仍有许多不足:1.不能准确识别音长、存在漏音和多音的现象。2.对midi音色过拟合。3.在麦克风录音时受到严重干扰。
因此在下一步我们打算:1.加入注意力机制,对音符序列进行建模。2.加大数据量。3.使用增加一些降噪手段,同时更真实的模拟麦克风的滤波。
真实样本结果
部分输入音频与输出音频结果如下(上方为输入音频,下方为输出后重构的音频),链接https://cloud.tsinghua.edu.cn/d/9273445e0ae54154a514/
1.千本樱
【音频:千本樱-输入】
【音频:千本樱-重构】
2.卡农
【音频:卡农-输入】
【音频:卡农-重构】
3.Chopin
【音频:Chopin-输入】
【音频:Chopin-重构】
4.时代前进
【音频:时代前进-输入】
【音频:时代前进-重构】
文献引用
[1].https://www.lunaverus.com/cnn




